
티스토리 뷰
최근 회사에서 서비스 개발을 진행하면서 이벤트 브로커를 사용해야할 일이 생겨서 카프카에 대해 알아보게 되었습니다.
사실 채팅을 구현하면서 Redis와 Kafka 사이 고민을 하고 각 장단점과 차이를 알아보고자 해당 내용을 공부하고 정리하게 되었습니다. 처음 접하는 구조와 생소한 많은 용어 때문에 여전히 혼란스럽지만... 우선 이해한 내용들을 바탕으로 정리를 해보려고 합니다. 🙏
Kafka란?
Kafka란 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트 스트리밍 플랫폼입니다. 카프카는 링크드인(Linked-In)에서 개발했습니다. 링크드인에서 카프카를 적용한 전체적인 그림을 보면 다음과 같습니다.

카프카를 적용함으로써
- 모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있게 되었고
- 새로운 서비스/시스템이 추가되어도 카프카가 제공하는 표준 포맷으로 연결하면 되므로 확장성과 신뢰성이 증가하였습니다.
- 또한 개발자는 각 서비스 간의 연결이 아닌 서비스들의 비즈니스 로직에 집중이 가능하게 되었습니다.
카프카의 동작 방식과 특징
카프카는 Pub-Sub 모델의 메시지 큐 형태로 동작하게 됩니다.
메시지 큐(Message Queue)란?
메시지 큐는 메시지 지향 미들웨어(Message Oriented Middleware)를 구현한 시스템으로 프로그램(프로세스) 간 데이터를 교환할 때 사용하는 기술입니다.

- Producer: 정보를 제공하는 자
- Queue: producer의 정보를 임시 저장 및 consumer에게 제공하는 곳
- Consumer: 정보를 제공받아 사용하는 자
여기서 중요한 것은 Queue인데 Message Queue에서 메시지는 Endpoint 간 직접 통신이 아닌 중간 Queue를 통해 중개가 된다는 것입니다.
MQ의 장점으로는
- 비동기 처리 가능: queue라는 임시 저장소가 있기 때문에 나중에 처리가 가능합니다.
- 낮은 결합도: 애플리케이션 별 분리가 가능합니다.
- 확장성: producer와 consumer 서비스를 원하는대로 확장할 수 있습니다.
- 탄력성: consumer 서비스가 다운된다고 하더라도 애플리케이션이 중단되는 것이 아니며 메시지는 지속하여 MQ에 남아있게 됩니다.
- 보장성: MQ에 들어간 모든 메시지는 결국 consumer에게 전달되는 것을 보장합니다.
❗️메시지 브로커 vs 이벤트 브로커
메시지 브로커란?
publisher가 생산한 메시지를 메시지 큐에 저장하고 subscriber가 가져갈 수 있도록 중간 다리 역할을 해주는 브로커(broker)라고 할 수 있습니다. 보통 서로 다른 시스템(혹은 소프트웨어) 사이에서 데이터를 비동기 형태로 처리하기 위해 사용합니다.
이러한 구조를 보통 pub/sub 구조라고 하며 대표적으로는 Redis, RabbitMQ 소프트웨어가 있고 GCP의 pubsub, AWS의 SQS와 같은 서비스가 있습니다.
이와 같은 메시지 브로커들은 subscriber가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터가 삭제되는 특성이 있습니다.
이벤트 브로커란?
이벤트 브로커 또한 기본적으로 메시지 브로커의 큐 기능들을 가지고 있어서 메시지 브로커의 역할도 할 수 있습니다.
그러나 이벤트 브로커는 producer가 생산한 이벤트를 이벤트 처리 후 바로 삭제하지 않고 저장하여 consumer가 특정 시점부터 이벤트를 다시 consume 할 수 있다는 장점이 있습니다. 또한 대용량 처리에 있어 더 많은 양의 데이터를 처리할 수 있는 능력이 있습니다.
대표적으로는 Kafka, AWS의 kinesis 같은 서비스가 있습니다.
카프카 구성요소 및 특징
Kafka를 구성하는 요소들을 하나씩 알아보겠습니다.
Zookeeper
분산 애플리케이션 관리를 위한 코디네이터 시스템입니다. 분산되어 있는 각 애플리케이션의 정보를 중앙에 집중하고 구성 관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공합니다. (해당 내용에 대한 자세한 사항은 별도로 다루도록 하겠습니다...!)
Broker
실행된 카프카 서버를 의미합니다. producer와 consumer는 별도의 애플리케이션으로 구성되는 반면, broker는 카프카 자체를 의미합니다. Broker(각 서버)는 Kafka Cluster 내부에 하나 이상 존재합니다. 각 서버 내부에 메시지를 저장하고 관리하는 역할을 수행합니다.
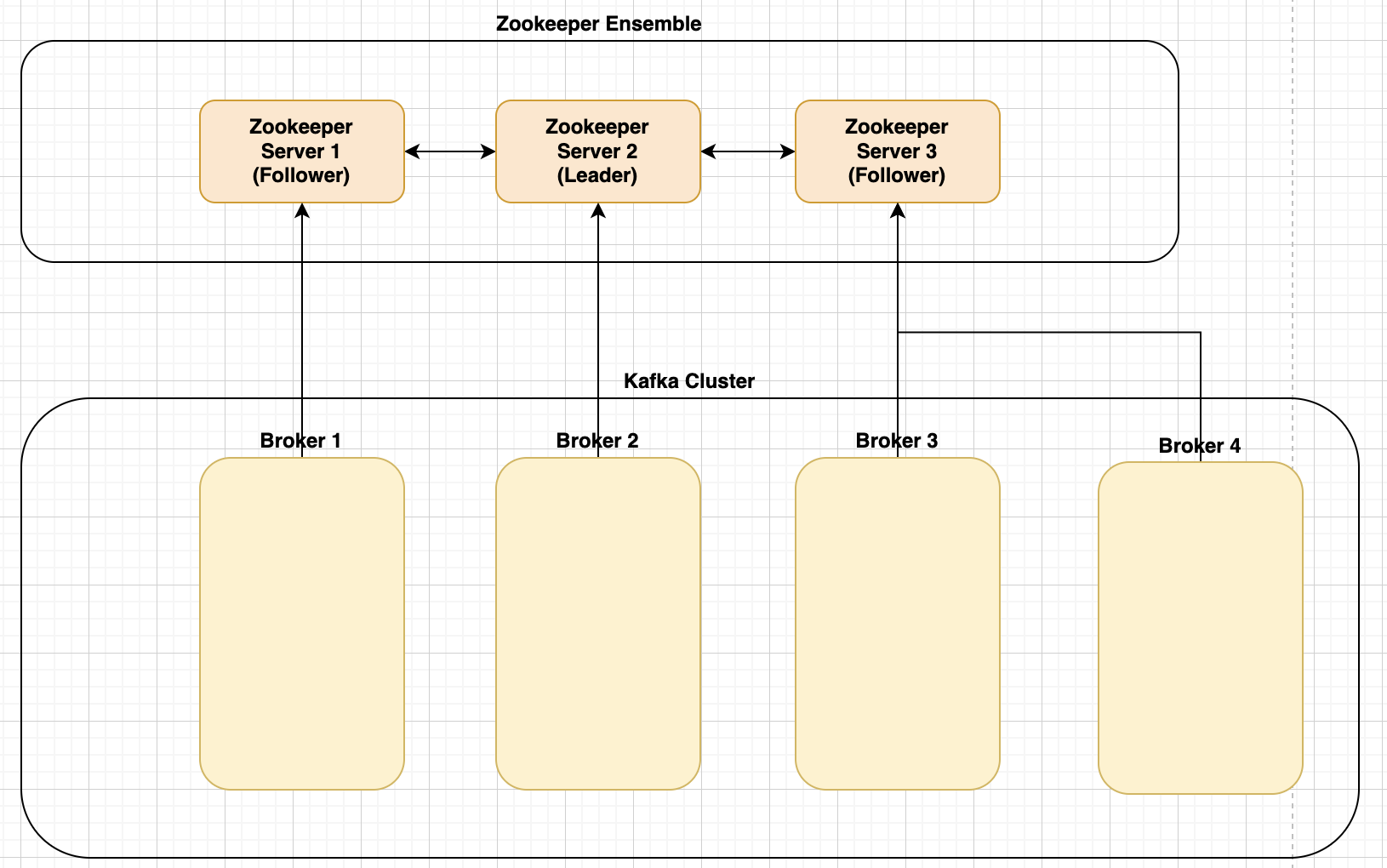
Partition
토픽을 분할하는 단위로 하나의 토픽은 여러개의 파티션을 가질 수 있습니다. 파티션의 개수는 변경이 가능한데 추가만 가능하고 삭제는 불가합니다. (토픽 자체를 지워야 전체 파티션이 삭제)
파티션이 하나라면 순서 보장이 가능합니다. 파티션 내부에서 각 메시지는 offset(고유번호)로 구분이 됩니다.
파티션이 여러개라면 Kafka 클러스터가 라운드 로빈 방식(default)으로 분배해서 분산처리되기 때문에 순서 보장을 할 수 없습니다. 파티션이 많을수록 처리량이 좋지만 장애 복구 시간이 늘어납니다.
Reflication
메시지를 복제해서 관리하고 특정 브로커에 장애가 발생했을 때 다른 브로커가 해당 브로커의 역할을 대신 수행할 수 있도록 하기 위한 기술입니다. 각 Topic 기준으로 Reflication 값을 지정할 수 있으면 기본적으로는 1입니다.
예를 통해 살펴보겠습니다.
Topic A - Partition 2, Reflication 1 / Topic B - Partition 1, Reflication 1 인 상황이라고 하면 그림은 다음과 같습니다.

Topic A - Partition 2, Reflication 2 / Topic B - Partition 1, Reflication 3 인 상황은 다음과 같습니다.

이때 원본은 Leader, 복제본은 Follower 라고 하는데 토픽으로 통하는 모든 데이터의 Read/Write는 Leader를 통해서만 이루어집니다. 이렇게 같은 파티션에 대해 Reflication으로 생성된 Leader와 Follower 를 묶어서 Reflication Group 이라고 하고 Leader 파티션이 있는 브로커에 장애가 발생한다고 하면 다른 같은 Reflication Group 내 다른 Follower가 Leader가 되는데 이러한 방식을 ISR(In-Sync Reflication)이라고 합니다.
중요한 데이터의 경우 Reflication 설정을 높여 안정성을 높일 수 있지만 데이터의 복제로 인한 성능 하락이 있을 수 있기 때문에 적절하게 조정하는 것이 중요합니다.

Topic
파티션의 모음이라고 할 수 있습니다. 각각의 메시지를 목적에 맞게 구분할 때 사용합니다. 메시지를 전송하거나 소비할 때 Topic을 반드시 입력합니다. 즉, Topic 단위로 producer가 메시지가 전송하고 consumer는 자신이 담당하는 메시지를 처리하게 됩니다.

Producer
메시지를 만들어 카프카 클러스터에 전송하는 주체입니다. 메시지 전송 시 Batch 처리가 가능합니다. key 값을 지정하여 특정 파티션으로만 전송하는 것도 가능합니다.
전송 ACKS 값을 설정하여 효율성을 높일 수 있습니다.
- ACKS=0 : 매우 빠르게 전송하며 파티션 리더가 받았는지 아닌지 알 수 없습니다.
- ACKS=1 : 파티션 리더가 받았는지 확인하는 방식으로 default 입니다.
- ACKS=ALL : 파티션 리더 뿐만 아니라 팔로워까지 메시지를 받았는지 확인하는 방식입니다.
Consumer
카프카 클러스터에서 메시지를 읽어서 처리하는 주체입니다. 메시지를 Batch로 처리할 수 있습니다. 한개의 consumer는 여러개의 topic을 처리할 수 있습니다.
consumer는 consumer group에 속하게 됩니다. 한개의 파티션은 consumer group 내 하나의 consumer에게만 연결이 됩니다. 따라서 consumer group 내 consumer 들은 동일한 토픽을 구독하고 있는 것이 일반적이고 하나의 토픽에 대해 하나의 consumer group에서 구독하는 consumer의 개수는 토픽의 파티션 개수와 맞추는 것이 좋습니다.


이렇게 카프카를 구성하는 여러 요소에 대해 개념적인 내용을 공부해보았는데요 Partition과 Consumer Group이라는 개념이 가장 생소하고 이해하기 어려웠던 부분이 많았던 것 같습니다. ㅠ
이를 바탕으로 다음에는 실제 카프카를 도커로 띄우고 서비스에서 Producer와 Consumer를 구성하여 테스트 해보도록 하겠습니다. (추가로 kafka 관련 도서를 읽고 내용이 추가, 변경될 수도 있습니다... 😅)
감사합니다.
참고
'기타' 카테고리의 다른 글
| [TypeORM] Node + Express 환경에서 TypeORM 사용하기 (0) | 2023.11.29 |
|---|---|
| [Socket.io] NodeJS + Express 기반 소캣 통신 서버 만들기 1 (0) | 2023.11.13 |
| [Redis] Redis username, password 설정하기 (0) | 2023.10.30 |
| [PostgreSQL] PostgreSQL String to Timestamp (1) | 2023.10.30 |
| [Real MySQL 8.0 북스터디] 04_아키텍처 (0) | 2023.03.01 |
- Total
- Today
- Yesterday
- Algorithm
- 프로그래머스
- cloudfront
- 수학
- spring
- ionic
- 조합
- BFS
- Baekjoon
- java
- SWIFT
- map
- EC2
- Dynamic Programming
- array
- 순열
- 에라토스테네스의 체
- 소수
- string
- search
- CodeDeploy
- CodePipeline
- CodeCommit
- permutation
- sort
- Combination
- AWS
- programmers
- ECR
- DFS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |